
GraphQL vs REST: Demonstrating the Difference with Real-World Examples
GraphQL vs REST has recently sparked much debate in an attempt to decide: which one is better for your project? In this article, we take a deep dive into the benefits and drawbacks of both, to help you make the best decision for your project.


Recently, there has been a lot of interest in GraphQL and its potential against REST. Teams are redesigning their API systems to support it, and you may be wondering if you should too. GraphQL certainly seems to provide a lot of benefits, but their scope is not easy to understand at first glance. Perhaps seeing a concrete example of a real software system, implemented with both REST and GraphQL frameworks would help us contrast the differences in a meaningful way. In this article, we will be doing just that, using Knowtworthy's meetings productivity platform as our sandbox.
What is GraphQL?
Like REST, GraphQL is a framework that defines communication between frontends and backends. Its benefits are numerous: preventing backend developers from re-writing the same code again and again, and optimizing complex API calls, to name just two. But in my opinion, the greatest benefit is its ability to structure endpoints so that they work well with graph-like data. GraphQL does all of this, independent of the kind of database you are using (for the most part, but the exceptions are best left for an article of their own).
For example, let’s take a look at the following:
A Knowtworthy Data Schema
In the graphic below, you can see a representation of the team data that we store at Knowtworthy, and how the entities relate to each other.
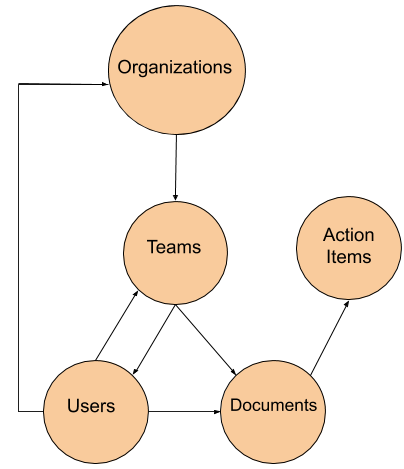
An Organization has Teams, and Teams have Users and Documents. Similarly, Users possess the inverse relationship: being part of Teams and Organizations, as well as Documents.
How the Client Queries for Data
In a REST architecture, the client interacts with endpoints, which are functions implemented on the backend. These functions have a pre-defined input-output behaviour, and don't have to interact with the data in any particular way (for example, treating it as a graph). This gives less structure to the backend developer, which can be a good thing if he/she is experienced and well versed in the project requirements. It also provides more encapsulation, as the frontend only needs to ask for the data, and not worry about how it was received.
On the other hand, GraphQL requires the client to understand the graph shown above. GraphQL defines certain entry points in the graph, and from those entry points, the client can traverse through the graph to get to other nodes.
query {
teams(name: "myTeam") {
users(name: "Johnny Appleseed") {
name
}
documents {
actionItems {
text
}
}
}
}In the example above, the client starts at a 'Teams' node, and then traverses down to get Users, then Documents, and then Action items. This can be powerful, as the client can query for any data in the graph that they want, and not have to request a specific endpoint for it. As a result, frontend developers using GraphQL will have to be a bit more invested in the backend data-architecture than if they were to use REST.
Backend Implementation:
When writing GraphQL endpoints, the only thing that the backend developer needs to worry about is how a specific node sends/updates its data, and connects with other nodes. You'll define the layout of a node's structure in a .graphql file like this:
type Team {
id: ID!
name: String
users: User[]
}Next, you'll define the logic for retrieving the id, name, and users in a separate resolver function. At this point, these functions are now similar to REST API endpoints, but they're structured to have a much more focused and atomic purpose.
The GraphQL Apollo server knows how to parse the GraphQL request on the client-side, and execute the corresponding resolver functions on the backend server. So, once you define the nodes and connections on the backend, Apollo can query requests from the client, and it will traverse the graph for you.
This can help us reduce the need to rewrite code, as we no longer have to write an endpoint for Org -> Team -> User, and another one for Org -> Team -> User -> Document. We just write them for Org, Team, User, and Document, and then Apollo will make the relevant connections for us.
In addition, an argument can be made that GraphQL is more scalable. For example, consider the case where we want to remove the Teams entity entirely. With a GraphQL implementation, we only need to change the incoming neighbours of Teams (i.e, one field on Organization, and one field on User). But with a REST implementation, this change can potentially require you to update every single endpoint on the backend server (assuming you don't use middleware).
Caching Benefits with GraphQL
With each traversal, GraphQL does some internal caching to speed up future requests. So, if you are doing two consecutive queries that each perform deep layers of nesting, GraphQL will use information found in the first traversal to make the second one quicker. We won't go too in-depth on this topic, but it's worth mentioning. We suggest visiting the Apollo website to learn more.
So, Should You Use GraphQL or REST?
GraphQL provides an intuitive structure to the API designer, and also possesses benefits regarding speed. However, it requires the frontend developers to be more informed about the backend data structure, and also may not work well for systems that are not graph-like in nature. REST endpoints are flexible, however with writing endpoints it's easy to fall into traps that can cause your code to be unscalable, repetitive, and complex. There are pros and cons with using any framework, and it's up to the developers to decide which tool is right for the job at hand and the future of the project.
We hope that you can use the examples provided in this article to help guide your decisions!